
“خليني أشيك على الـ KPIs قبل ما نبدأ الـ sprint review.”
Feed the utterance above into almost any off-the-shelf speech engine and you’ll see chaos: prefixes glued to English words, half-heard dialect vowels, and salient keywords gone. To make sense of blended Arabic and English speech, we built a code-switch-aware ASR that cuts through that chaos:
While speech AI adoption surges globally, enterprises across the MENA region face a unique linguistic reality that most off-the-shelf solutions simply weren't built to handle: Customers switch fluidly between Arabic dialects (Najdi, Hijazi, Egyptian, Levantine, etc.), and English, often switching mid-sentence or even mid-word.
This isn't a minor inconvenience—it's a fundamental mismatch. ASR models, even multilingual ones, stumble when confronted with this linguistic complexity, and those mistranscriptions turn into real business pain downstream: incomprehensible meeting minutes, frustrated agents spending precious minutes correcting transcripts, and customer experiences that fall short of expectations. The opportunity is massive, but so is the challenge.
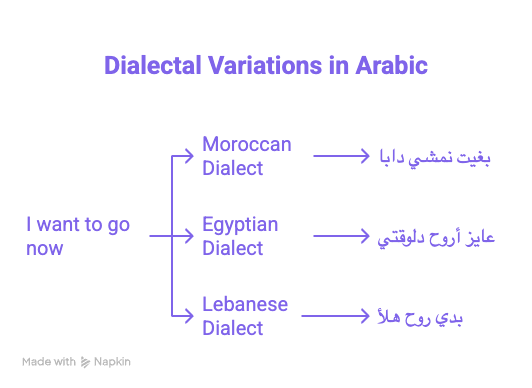
A Moroccan saying "I want to go now" says "بغيت نمشي دابا" in Moroccan Arabic; an Egyptian says "عايز أروح دلوقتي", and a Lebanese says "بدي روح هلأ". Each dialect represents the same meaning using unique vocabulary and structure. Even within the same country, such as Egypt, a Cairene and an Alexandrian speak different dialects. In all of these colloquial dialects, there are no strict grammar or morphology rules (like in Modern Standard Arabic), which complicates machine learning. An ASR system trained on one dialect might completely fail on another, despite both being Arabic.
Arabic writing creates transcription challenges. The same letter may take multiple forms, for example the letter Alif appears as:
When someone says a word with the "ah" sound, which form should the system choose? Context, grammar, and word origin all matter.
Words ending in تاء مربوطة (taa marbouta) are often mistranscribed as هاء (haa) since they sound identical. "مدرسة" (school) might appear as "مدرسه" (his teacher) in transcripts.
Tashkīl, a subset of the diacritical marks in Arabic, adds even more complexity. Adding these small marks to the exact same letters can change their meaning completely! For example:
Arabic packs extensive meaning into single words through affixes, expressing what typically requires multiple English words. For example, consider سَيَكْتُبونَها (“they will write it”):
This morphological density creates difficulties for systems expecting clearer word boundaries like those in English.
Arabic — spoken in professional settings — presents an even greater challenge: seamless Arabic-English blending within conversations. It is typical to hear many English words mixed within Arabic ones in the same sentence:
"بنحاول نعمل ابديت للبروجكت قبل الديدلاين عشان الكلاينت مستعجل"
This phenomenon mixes Arabic morphology with English terms (e.g., "update," "project," "deadline," and "client") and adapts them to Arabic pronunciation (arabization). This isn't just inserting English words; it's productive blending that creates new words and grammar rules using both languages at the same time.
Speakers "Arabize" English terms phonetically, creating hybrid forms that confuse recognition systems:
Technical terms can get partially Arabized: "حنعمل باك-أب للداتا قبل التحديث" (We'll create a backup of the data before the update).
Moreover, we observe increased productivity (the ability to create novel expressions, such as plurals):
The most complex challenges emerge where Arabic and English morphological systems collide.
Arabic prefixes attach directly to English terms. The definite article "ال" frequently joins English nouns:
Arabic prepositions also attach:
The most complex are Arabic verb conjugations with English terms:
Moreover, other affixes can still pile on:
These boundary-crossing phenomena challenge ASR systems to simultaneously apply rules from two linguistic systems while recognizing novel hybrid forms, which do not follow a standard set of rules given their colloquial nature. These Arabic code-switching challenges represent fascinating frontiers where linguistic creativity meets computational constraints, pushing developers to rethink fundamental assumptions about language processing.
Our research identified Whisper as a promising foundation to build upon. While the base version of Whisper-large-v3 represents the current state-of-the-art for many speech recognition tasks, it still struggled with the complex linguistic patterns found in code-switched Arabic-English speech.
Our specialized fine-tuning approach significantly enhanced Whisper's ability to handle these unique patterns. By focusing specifically on the challenges of code-switching, our model achieved a 27% relative improvement in word error rate compared to the base Whisper-large-v3 model.
This improvement represents a substantial leap forward in quality. Our 27% reduction transforms what would have been a frustrating experience with frequent errors into a system that reliably captures the natural flow of bilingual conversation.
Beyond model improvements, we developed a normalization pipeline that enhances transcription quality for code-switched content by resolving the linguistic phenomena that occur when Arabic and English intermingle in natural speech.
Our approach focuses on a morphological analysis system that understands word construction in both languages. It recognizes internal word structure and handles cases where Arabic morphological elements blend with English words (as illustrated above).
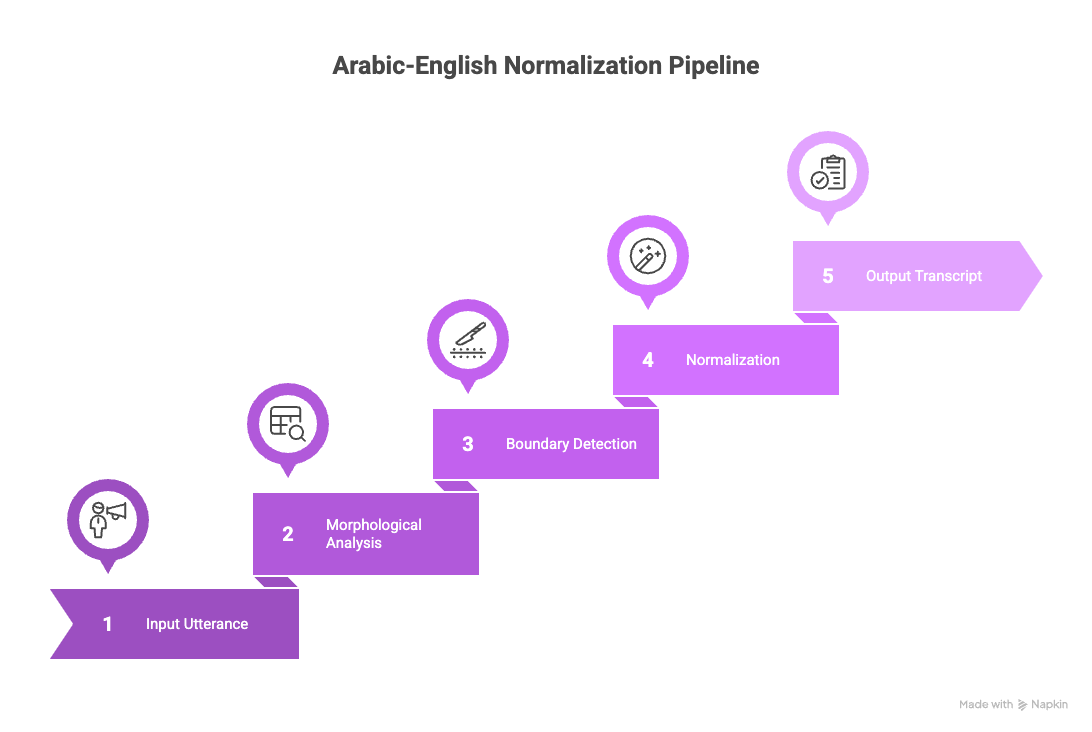
The pipeline intelligently detects morphological boundaries and produces correct bilingual interpretations. When a speaker says "عملنا إنفيستيجيشن للايشو" (we did an investigation of the issue), our system properly identifies and normalizes the English terms within the Arabic structure when the ASR model doesn’t produce the intended output.
These technical improvements translate directly to tangible business value for organizations operating in Arabic-speaking regions:
In addition to the quantitative improvement in word error rate, qualitative feedback from early adopters reveals significantly higher satisfaction with transcription quality. Users particularly note how well the system handles technical terminology that frequently triggers code-switching in professional settings.
Arabic-English code-switching presents unique challenges that have long hindered speech recognition in professional MENA contexts. Our solution addresses these head-on with a specialized fine-tuned Whisper model that achieves a 27% improvement in word error rate, combined with an advanced normalization pipeline that intelligently handles the complex morphological blending where Arabic and English intersect.
This isn't just a technical achievement—it's a business enabler. Our system captures the natural language patterns professionals actually use, transforming what were once frustrating, error-prone transcriptions into reliable tools that enhance productivity across meeting documentation, customer support, compliance monitoring, and knowledge management.
For organizations operating in multilingual environments, particularly in the rapidly growing MENA market, this represents a competitive advantage. While generalized ASR solutions require users to adapt their speech, our technology adapts to how people naturally communicate.
Ready to see it in action? Try our demo to experience accurate Arabic-English code-switching recognition firsthand.
Want to integrate advanced speech AI into your existing systems or build a custom solution? Contact us to discuss how we can help unlock the full potential of multilingual speech technology for your organization.




